Daten & Statistik
KLAUSUR-LÖSUNGEN & ERKLÄRUNGEN · 7 AUFGABEN
Diese Seite erklärt sieben Klausuraufgaben aus Daten und Statistik Schritt für Schritt — anfängergerecht, mit Formeln und Grafiken. Das Kürzel KI steht hier durchgehend für Konfidenzintervall, nicht für künstliche Intelligenz.
Hinweis zu Frage 5: Die Aussagen a) und c) sind konventionsabhängig — ihre Richtigkeit hängt von den genauen Definitionen im Skript ab. Diese Stellen sind transparent als „Wenn-Dann" gekennzeichnet.
Eigenschaften des Konfidenzintervalls für p̂
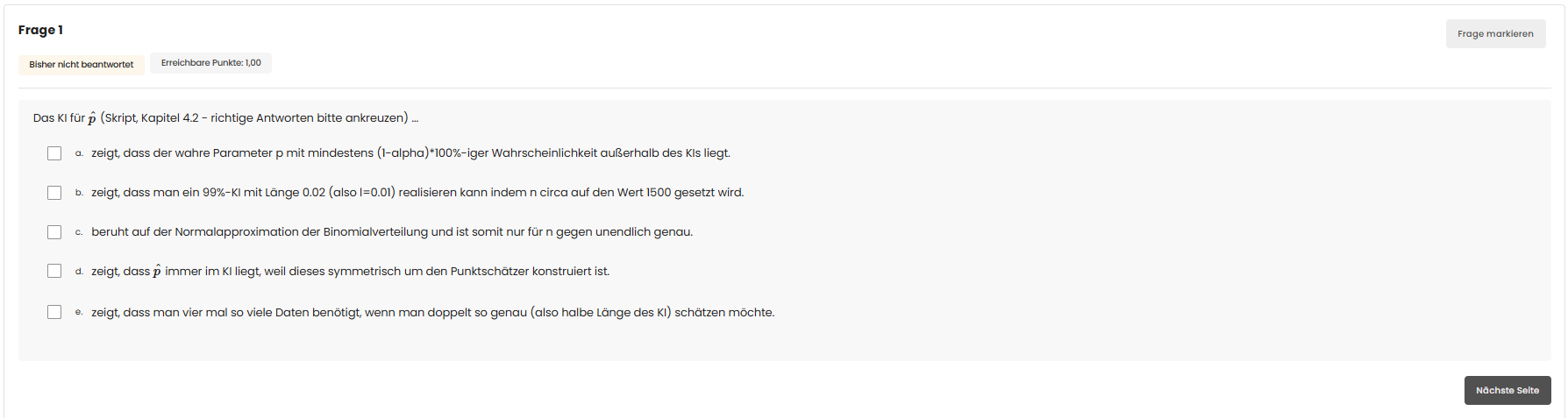
Optionen & Bewertung
Ausführliche Erklärung
Für Einsteiger: Was ist ein Konfidenzintervall?
Man zieht eine Stichprobe und berechnet einen Bereich (Intervall), in dem der unbekannte wahre Wert $p$ mit hoher Wahrscheinlichkeit liegt. „95%-KI" heißt: Würde man das Experiment sehr oft wiederholen und jedes Mal ein Intervall berechnen, wären 95 % dieser Intervalle so gebaut, dass sie $p$ enthalten. Der wahre Wert ist fix — das Intervall ist zufällig.
Was ist p̂? Das ist die beobachtete relative Häufigkeit von Erfolgen in der Stichprobe — der Punktschätzer für die unbekannte Erfolgswahrscheinlichkeit $p$. Das Wald-KI baut darauf auf:
Die Länge $l$ und der Stichprobenumfang: Mit der Notation $l$ für den halben Abstand (Margin) gilt im konservativen Worst-Case ($p(1-p) \leq \tfrac14$):
Weil $n$ mit $l^{-2}$ skaliert, verdoppelt man die Genauigkeit (halbiertes $l$) nur durch Vervierfachung des Aufwands. Das ist Aussage e).
Grafik A — KI-Überdeckung (Wiederholungsexperiment)
Grafik A — 9 von 10 Intervallen überdecken den wahren Wert p (schematisch für 90%-Niveau)
Grafik B — Stichprobenumfang n skaliert mit 1/l²
Grafik B — Halbierung der Genauigkeit l₀ → Vervierfachung des Stichprobenumfangs
Welche Methode für welche Fragestellung?
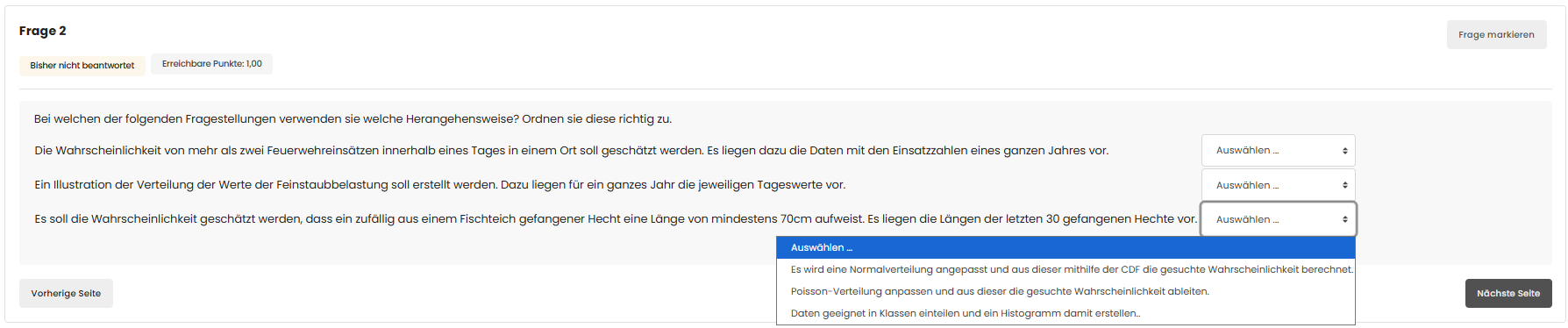
Korrekte Zuordnungen
| Fragestellung / Szenario | Richtige Methode |
|---|---|
| Wahrscheinlichkeit von mehr als zwei Feuerwehreinsätzen innerhalb eines Tages; Daten = Einsatzzahlen eines ganzen Jahres. | Poisson-Verteilung anpassen und daraus die gesuchte Wahrscheinlichkeit ableiten. |
| Illustration der Verteilung der Feinstaubbelastung; Daten = Tageswerte eines ganzen Jahres. | Daten geeignet in Klassen einteilen und ein Histogramm erstellen. |
| Wahrscheinlichkeit, dass ein gefangener Hecht ≥ 70 cm lang ist; Daten = Längen der letzten 30 Hechte. | Normalverteilung anpassen und daraus mithilfe der CDF die gesuchte Wahrscheinlichkeit berechnen. |
Ausführliche Erklärung
Für Einsteiger: Die drei Faustregeln
- Anzahl seltener Ereignisse pro Zeit (Feuerwehr, Anrufe, Treffer) → Poisson-Verteilung
- Stetige Messgröße + Wahrscheinlichkeit eines Bereichs (Länge, Gewicht, Temperatur) → Normalverteilung + Verteilungsfunktion (CDF)
- Nur darstellen, wie die Daten verteilt sind (kein Modell gefragt) → Histogramm
Beim Hecht-Beispiel sucht man $P(X \ge 70)$. Man passt eine Normalverteilung an (Mittelwert und Standardabweichung aus den 30 Messwerten schätzen) und berechnet:
Grafik C — Normalverteilung: P(X ≥ 70) als Fläche
Grafik C — Schattierte Fläche rechts von x = 70 entspricht P(X ≥ 70) = 1 − F(70)
Grafik D — Histogramm (Feinstaubbelastung, schematisch)
Grafik D — Schematisches Histogramm: Feinstaubwerte in Klassen eingeteilt
Poisson-Verteilung an Daten anpassen
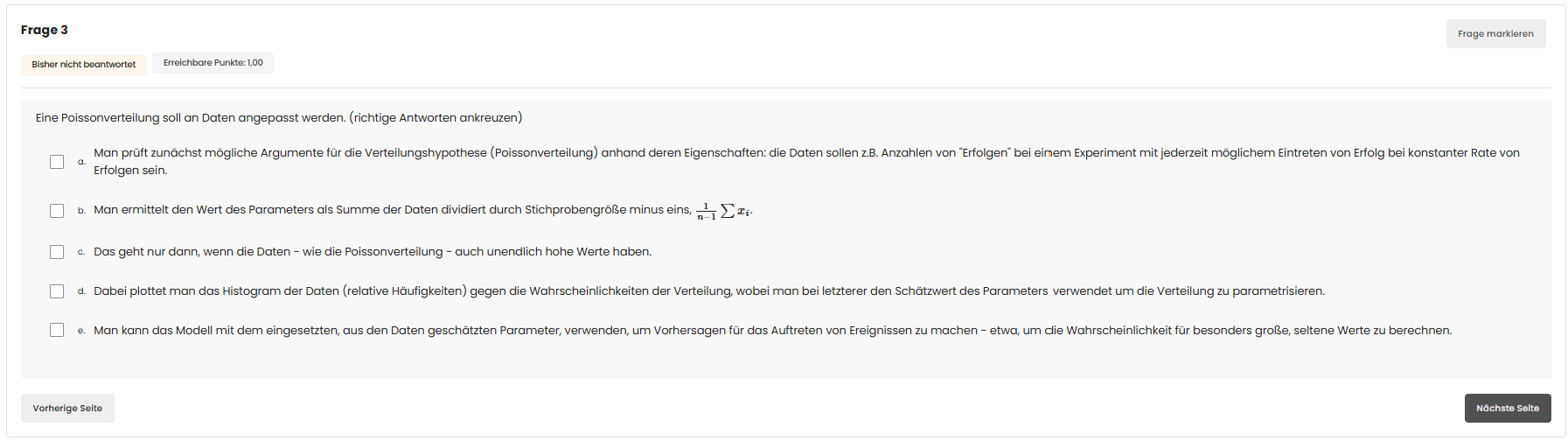
Optionen & Bewertung
Ausführliche Erklärung
Für Einsteiger: Was ist die Poisson-Verteilung?
Die Poisson-Verteilung beschreibt, wie oft ein Ereignis innerhalb eines festen Zeit- oder Raumintervalls auftritt — vorausgesetzt, die Ereignisse treten unabhängig voneinander mit konstanter Rate λ auf. Typische Beispiele: Feuerwehreinsätze pro Tag, Anrufe pro Stunde, radioaktive Zerfälle pro Sekunde.
Der richtige λ-Schätzer: Bei der Poisson-Verteilung gilt $E[X] = \lambda$ und $\text{Var}(X) = \lambda$. Der beste (unverzerrte) Schätzer für λ ist einfach der Stichprobenmittelwert:
Brückenschlag zu Frage 6c
Option b) schlägt $\frac{1}{n-1}\sum x_i$ vor — das ist falsch als Schätzer. Aber in Frage 6c wird gezeigt: Dieser Ausdruck ist asymptotisch erwartungstreu, weil $E\!\left[\frac{1}{n-1}\sum x_i\right] = \frac{n\lambda}{n-1} \to \lambda$ für $n \to \infty$. Für endliches n ist er leicht zu groß — und eben nicht korrekt.
Grafik E — Histogramm der Daten vs. Poisson-PMF
Grafik E — Vergleich Daten-Histogramm vs. Poisson-PMF mit geschätztem λ (schematisch)
Konfidenzintervalle für den Mittelwert — Schützenfisch
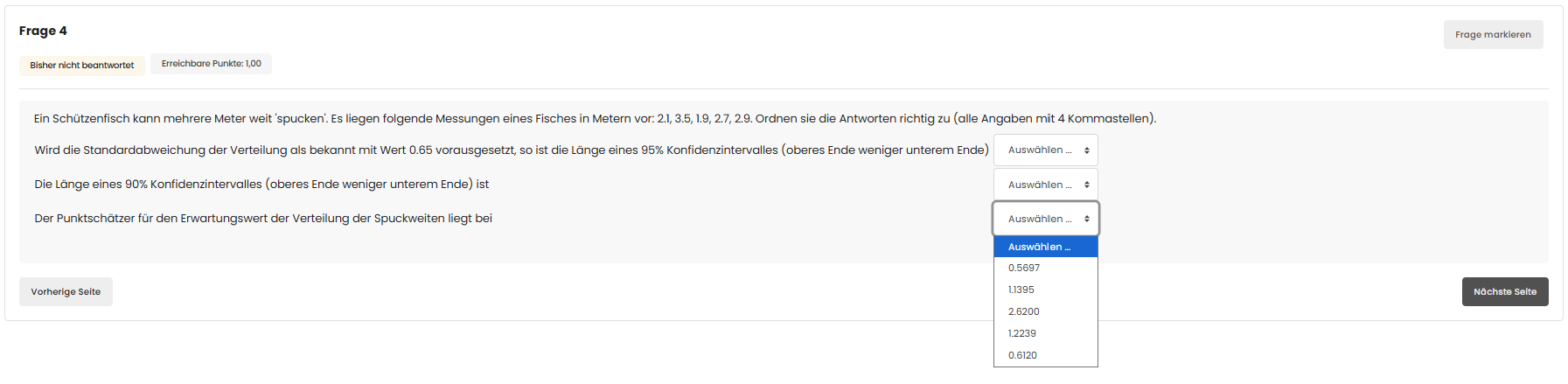
Gegebene & berechnete Größen
Vorberechnete Größen
$n = 5$,
$\bar{x} = \frac{2{,}1 + 3{,}5 + 1{,}9 + 2{,}7 + 2{,}9}{5} = \frac{13{,}1}{5} = 2{,}62$
$s = \sqrt{\frac{1}{n-1}\sum(x_i - \bar x)^2} = 0{,}6419$ (Stichproben-Std., ddof = 1)
Korrekte Zuordnungen
Standardabweichung bekannt = 0,65 — Länge eines 95%-KI (oberes minus unteres Ende)
= 1,1395
$L = 2\,z_{0{,}975}\,\dfrac{\sigma}{\sqrt{n}} = 2 \cdot 1{,}95996 \cdot \dfrac{0{,}65}{\sqrt{5}} \approx 1{,}1395$
Standardabweichung unbekannt — Länge eines 90%-KI (t-Verteilung)
= 1,2239
$L = 2\,t_{0{,}95,\,4}\,\dfrac{s}{\sqrt{n}} = 2 \cdot 2{,}13185 \cdot \dfrac{0{,}6419}{\sqrt{5}} \approx 1{,}2239$
Punktschätzer für den Erwartungswert
= 2,6200
Das ist einfach der Stichprobenmittelwert $\bar x = 2{,}62$.
Ausführliche Erklärung
Wichtig: Wann z, wann t?
σ bekannt (explizit gegeben = 0,65): Man verwendet die
Standard-Normalverteilung (z-Wert). Das KI ist schmäler,
weil keine Unsicherheit über σ besteht.
σ unbekannt (nur Stichproben-Std. s verfügbar): Man verwendet die
t-Verteilung (df = n − 1 = 4). Die t-Verteilung hat breitere
Enden als die Normalverteilung — das KI wird breiter, um die Unsicherheit über σ
zu berücksichtigen.
Für Einsteiger: Was ist die „Länge" eines KI?
Ein KI sieht so aus: $[\bar x - \text{Margin},\; \bar x + \text{Margin}]$. Die Länge ist der Abstand zwischen den Enden: $L = \text{oberes Ende} - \text{unteres Ende} = 2 \cdot \text{Margin}$. Die Distraktoren 0,5697 und 0,6120 entsprechen den halben Längen (den Margins) — Achtung, Falle!
Für das 95%-KI mit bekanntem σ gilt $z_{0{,}975} = 1{,}95996$ (z-Quantil), für das 90%-KI mit unbekanntem σ (df=4) gilt $t_{0{,}95,\,4} = 2{,}13185$ (t-Quantil, der wegen kleiner Stichprobe und Unsicherheit über σ größer ist).
Beachte: Obwohl 90% < 95%, ist das zweite KI länger — weil der t-Quantil bei df=4 deutlich größer ist als z, und weil σ unbekannt ist. Ab großen Stichproben nähern sich z und t an.
Grafik F — Schützenfisch: Daten und Konfidenzintervalle
Grafik F — Schützenfisch: 5 Datenpunkte, Mittelwert x̄ = 2,62 und die zwei KIs
Eigenschaften von Schätzern
Optionen & Bewertung
Ausführliche Erklärung
Für Einsteiger: Was ist ein Schätzer?
Ein Schätzer ist eine Rechenvorschrift, die aus Daten einen Wert für einen unbekannten Parameter berechnet. Zum Beispiel: $\bar x = \frac{1}{n}\sum x_i$ schätzt den unbekannten Erwartungswert $\mu$. Weil die Daten zufällig sind, ist auch das Ergebnis des Schätzers zufällig — verschiedene Stichproben geben verschiedene Schätzwerte.
Erwartungstreue ($E[\hat\theta] = \theta$): Im Durchschnitt (über alle möglichen Stichproben) trifft der Schätzer den wahren Wert. Kein Einzelresultat muss exakt passen. Beispiel: $\bar x$ ist erwartungstreu für $\mu$.
Konsistenz: Mit wachsendem Stichprobenumfang wird der Schätzer immer genauer — die Wahrscheinlichkeit einer großen Abweichung geht gegen null.
Achtung: a) und c) hängen vom Skript ab
Falls in der Klausur a) oder c) gefordert ist: Schau in die Skript-Definitionen. Diese Seite kann keine bindende Aussage machen, da die Klassifikation (parametrisch/nicht-parametrisch) und die Definition der „empirischen Standardabweichung" (Nenner n vs. n−1) lehrstuhlspezifisch sind.
Asymptotische Erwartungstreue
Optionen & Bewertung
Ausführliche Erklärung
Für Einsteiger: Asymptotische Erwartungstreue
Ein Schätzer muss nicht für alle n perfekt sein. Es reicht, wenn er im Grenzfall (große Stichprobe) im Mittel den richtigen Wert liefert: $E[\hat\theta_n] \to \theta$ für $n \to \infty$. „Asymptotisch" bedeutet: gilt erst für große n, nicht unbedingt für kleine.
Verbindung zu Frage 3b
In Frage 3 war $\frac{1}{n-1}\sum x_i$ als λ-Schätzer falsch — denn der korrekte (unverzerrte) Schätzer ist $\frac{1}{n}\sum x_i$. Hier in Frage 6 ist derselbe Ausdruck richtig — weil die Frage nur nach asymptotischer Erwartungstreue fragt, und die gilt. Beide Aussagen sind konsistent und ergänzen sich.
Warum ist b) falsch? Geometrische Verteilung: $P(X=k) = (1-p)^{k-1}\!p$, $E[X] = 1/p$. Wenn $1/\bar x$ für $p$ konvergiert, dann konvergiert er gegen das Inverse des Erwartungswertes — nicht gegen den Erwartungswert selbst. Man würde daher $\bar x$ (nicht $1/\bar x$) als Schätzer für $E[X] = 1/p$ nehmen.
Konfidenzintervalle & Stichprobenumfang für Anteile — Brieflose
Konservatives KI — Worst-Case-Annahme
Diese Aufgabe verwendet das konservative Konfidenzintervall: Statt $p(1-p)$ mit dem geschätzten $\hat p$ zu berechnen, nimmt man den Worst-Case-Wert $p(1-p) \le \tfrac{1}{4}$ (Maximalwert bei $p=0{,}5$). Der Margin ist dann: $$M = z \cdot \frac{0{,}5}{\sqrt{n}}$$ Der Vorteil: Das Intervall ist sicher breit genug, egal wie $\hat p$ ausfällt.
Korrekte Zuordnungen
Gewinnwahrscheinlichkeit mit 95%-iger Sicherheit auf ±1 % einschätzen ⇒ so viele Lose kaufen:
= 9604
$n = \left(\dfrac{z \cdot 0{,}5}{l}\right)^{\!2} = \left(\dfrac{1{,}95996 \cdot 0{,}5}{0{,}01}\right)^{\!2} = 97{,}998^2 \approx 9604$ (auf die nächste ganze Zahl aufgerundet)
15 Lose, 4 Gewinne — 90%-KI: Margin (konservativ)
= 0,2123
$M = z_{0{,}95} \cdot \dfrac{0{,}5}{\sqrt{15}} = 1{,}64485 \cdot \dfrac{0{,}5}{\sqrt{15}} \approx 0{,}2123$ (Distraktor 0,4246 = volle Länge = 2·Margin!)
10 Lose, 2 Gewinne — 90%-KI, unterer Rand
= 0
$\hat p = 2/10 = 0{,}2$. Naiver unterer Rand: $0{,}2 - 1{,}64485 \cdot \dfrac{0{,}5}{\sqrt{10}} = 0{,}2 - 0{,}2601 = -0{,}0601$. Da $p \in [0,1]$, wird auf 0 geclippt. Distraktor −0,0601 = nicht-geclippter (falscher) Wert.
Ausführliche Erklärung
Für Einsteiger: Margin vs. Länge vs. Rand
- Margin (= halbe Länge) $M = z \cdot 0{,}5/\sqrt{n}$: der Abstand vom Mittelpunkt zum Rand.
- Länge $L = 2M$: Abstand unteres → oberes Ende.
- Unterer Rand $= \hat p - M$ (aber nie < 0).
- Oberer Rand $= \hat p + M$ (aber nie > 1).
Clipping auf [0,1]: Wenn der rechnerische Rand negativ wird (wie hier −0,0601), ist das physikalisch sinnlos — Wahrscheinlichkeiten sind nie negativ. Daher setzt man den unteren Rand auf max(0, unterer Rand) = 0.
Grafik — Clipping: Intervall ragt unter 0, wird abgeschnitten
Das rohe KI ragt unter 0 (rot gestrichelt) — es wird auf den gültigen Bereich [0,1] geclippt (grün)
Warum z0,95 = 1,64485? Beim zweiseitigen 90%-KI verteilen sich die 10 % auf beide Seiten: je 5 % oben und unten. Daher nimmt man das 95%-Quantil der Standardnormalverteilung.
Jupyter-Notebook: Daten_und_Statistik_KIs.ipynb
Das Notebook notebook/Daten_und_Statistik_KIs.ipynb berechnet
die konkreten Konfidenzintervalle und Stichprobenumfänge der Klausur
(Fragen 1, 4 und 7) und gibt die Ergebnisse zur Selbstkontrolle aus.
Es wird nicht auf dieser Seite beschrieben — die Erklärungen
stehen in den Fragen-Sektionen oben.
Aufbau des Notebooks
Abschnitt A — Mittelwert-KI (Frage 4)
Eingabe: daten = [2.1, 3.5, 1.9, 2.7, 2.9], sigma_bekannt = 0.65,
Konfidenzniveaus (95 % für bekanntes σ, 90 % für unbekanntes σ).
Berechnet: Mittelwert, Stichproben-Std. (ddof = 1), KI bei bekanntem σ (z-Wert)
und bei unbekanntem σ (t-Wert, df = n−1 = 4). Ausgabe: Länge, Margin, Intervall,
Punktschätzer.
Abschnitt B — Anteils-KI & Stichprobenumfang (Fragen 7 & 1)
Eingabe: erfolge, versuche, Konfidenzniveau, gewünschte
Genauigkeit l. Berechnet konservativen Margin $z \cdot 0{,}5/\sqrt{n}$,
clipped auf [0,1], sowie Stichprobenumfang
$n = \lceil (z \cdot 0{,}5 / l)^2 \rceil$.
Was und wo ändern
Alle austauschbaren Eingaben sind mit einem Kommentarblock
# ===== HIER WERTE ÄNDERN ===== markiert: Daten-Liste,
bekannte Standardabweichung σ, Konfidenzniveau, erfolge/versuche,
gewünschte Genauigkeit l. Einfach nur diese Blöcke anpassen und
die Zelle neu ausführen.
Codeauszug (Vorschau)
Erwartete Ausgaben (zur Selbstkontrolle)
Erwartete Ergebnisse
- Frage 4 — Länge 95%-KI (σ bekannt): 1,1395
- Frage 4 — Länge 90%-KI (σ unbek., t): 1,2239
- Frage 4 — Punktschätzer x̄: 2,6200
- Frage 7 — Stichprobenumfang (±1%, 95%): 9604
- Frage 7 — Margin (15 Lose, 90%, konservativ): 0,2123
- Frage 7 — Unterer Rand (10 Lose, 2 Gewinne, 90%): 0
Voraussetzungen & Start
Benötigt: Python mit numpy und scipy.
Starten mit Jupyter (jupyter notebook) oder direkt in
VS Code (Jupyter-Extension). Alle Pakete per
pip install numpy scipy installierbar.